I introduce a python package geochemdb, which is my attempt to organize geochmical data into a responsibly managed database.
Problem: lots of data
Over the course of my PhD, I have generated a considerable number of measurements of the U, Pb, and trace element composition of zircons. Almost all of these measurements are from the UCSB Petrochronology Lab, where a split-stream laser ablation setup means that a single spot analysis can yield these measurements on separate ICPMS instruments simultaneously.
These measurements are organized by the experiments during which they were collected, colloquially “laser runs.” The data must be reduced for each laser run, which I do using the iolite 4 software. There are at least as many reduced data files (typically .csv or .xlsx) as there are laser runs, which at this point number in the dozens.
It quickly becomes unwieldy to keep track of each reduced data file as well as which samples were analyzed on which runs. Furthermore, iolite 4 does not currently permit (to my knowledge) the outputs of different data reduction schemes to simultaneously persist in the same session. It is therefore necessary to output data reduction for U and Pb isotopes separately from trace elements, yielding two separate files for each split-stream run. Finally, I have other geochemical datasets, from CA-ID-TIMS on many of the same zircons I have LA-ICPMS data for, as well as XRF measurements on hundreds of shale powders. It would be convenient if all of this data could live in the same place and play by the same rules.
Solution: easy-to-manage database
All this to say that the time came to develop a database of my geochemical measurements, along with python code to add, update, and retrieve data vis-a-vis the database. I’ve opted for a SQLite embedded database, managed by a python package named geochemdb.
Alternatives
Briefly before getting into the details, here are some other alternatives I considered:
- Sparrow: This seems like a great project for implementing FAIR data standards, but it’s really geared for deployment at the lab scale. It would be great to deploy an instance for UCSB, but it seems like overkill for a personally managed geochemistry database.
- Served relational database (MariaDB, PostgreSQL, etc.): A step down from deploying Sparrow would be to serve a dedicated relational database, maybe in a docker container an old Raspberry Pi or something. Again, it’s overkill, since I don’t have that much data, and I don’t need network access or concurrent querying. The less infrastructure I have to run, the better.
- Iolite 4 database: Iolite 4 actually provides a feature to build a sqlite database from multiple iolite sessions. I played around with it, but the main issue is that, because a session cannot hold output channels simultaneously from two different data reduction schemes, the resulting sqlite database cannot really accept split-stream data. I also have way less control over the database struture, and it’s not at all straightforward to add more tables to track key metadata (more below).
SQLite does not require a server, and it just operates from a single .db file that contains all of the data and data relations. So far, I’ve enjoyed using
SQLiteStudio to manage the database structure, which shields me from a lot of tedious SQL queries.
Database Structure
Having selected a database platform to use, the next hurdle is developing the schema, which is basically the set of tables, their columns, and how they relate to each other. This process has forced me to think a lot about the nature of data collection:
- what constitutes an “analysis”
- how do we label measured materials (sample, zircon, spot, etc)
- how can concepts be generalized so that measurements from LASS-ICPMS, ID-TIMS, handheld XRF, etc. can coexist in the same database.
I think the schema will be an evolving thing, but what is presented below draws heavily on articles by Chamberlain et al. (2021)1 and Staudigel et al. (2003)2 regarding the minimum metadata that should accompany geochemical data.
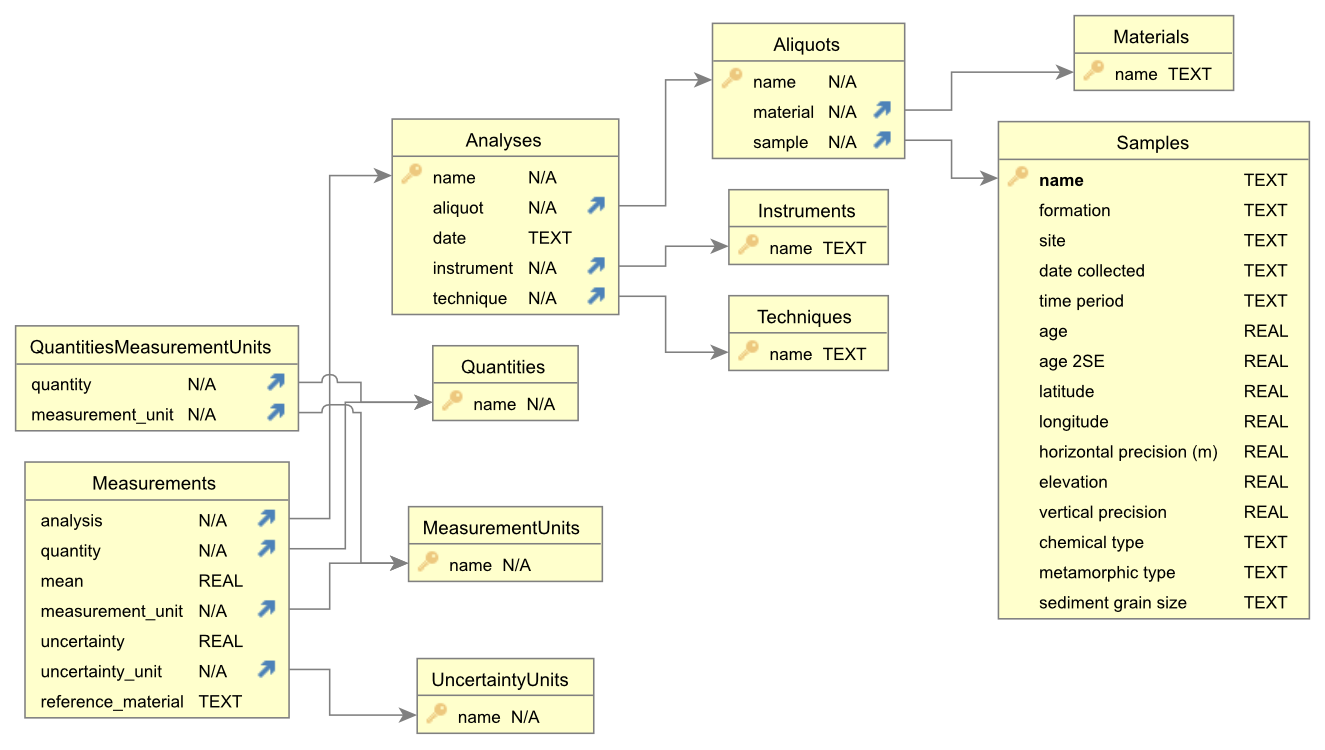
Schema for database of geochemical data.
The details of this schema are presented in the geochemdb readme, which explains each table and its columns.
geochemdb
With the database structure defined, I developed geochemdb, which is a very simple python package that facilitates interaction with the database. It makes it easy to
- add,
- update, and
- retrieve
geochemical measurements from the database, eliminating the hassle of managing dozens of potentially duplicated spreadsheets. The workflow simultaneously enforces the registration of important metadata.
I have prepared a Jupyter notebook tutorial for using the package, and the package can be installed from pypi with pip install geochemdb.
I’ve been using geochemdb for several months now, and I have migrated all of my zircon geochemistry data into a single database file. This 24 MB file contains over 13,000 analyses and over 250,000 measurements, all of which I can access with 3 lines of code:
import geochemdb
db = geochemdb.GeochemDB('path/to/mydatabase.db')
measurements_df = db.measurements_by_sample('sample name')
I wish I had sorted this out at the beginning of my PhD, but better late than never!
References
Chamberlain, K.J., Lehnert, K.A., McIntosh, I.M., Morgan, D.J., and Wörner, G., 2021, Time to change the data culture in geochemistry: Nature Reviews Earth & Environment, v. 2, p. 737–739, doi:10.1038/s43017-021-00237-w. ↩︎
Staudigel, H. et al., 2003, Electronic data publication in geochemistry: Geochemistry, Geophysics, Geosystems, v. 4, doi:10.1029/2002GC000314. ↩︎